BE COMPUTER SCIENCE.
SUBJECT : HIGH PERFORMANCE COMPUTING.
YEAR : DEC 2017
Q1) a) Explain SIMD, MIMD and SIMT architecture.
1 SIMD(Single Instruction Multiple Data).
- i) In SIMD (Single Instruction Multiple Data) as the name suggests single instruction works on several data items simultaneously by using several processing elements (PEs). All of which carry out the same operation.
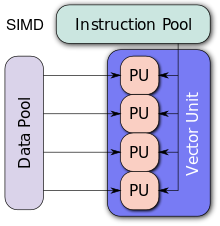
- ii) It uses single Control Unit to dispatch multiple instruction to various processing elements.
iii) In SIMD computing model a single control unit is used to read instructions by a single Program Counter (PC), decoding them and sending control signals to the PE’s.
- iv) The number of data paths depends upon number of Processing Elements. The data is supplied and derived from PEs by the memory.
Fig. Processor Array
- v) The different units like PEs and memory modules are interconnected by interconnection networks. The data transfers to and from the PEs are managed by interconnected networks.
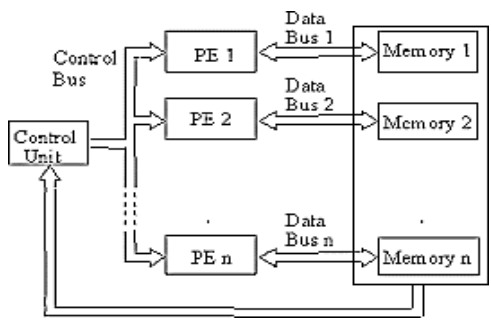
- MIMD (Multiple Instruction Multiple Data).
- i) As the name suggests, in this model multiple instructions are executed on multiple data items simultaneously.
- ii) Most of the multiporcessing system comes under this category of the system. MIMD is maily used for parallel computations, to execute set of instructions parallely.
iii) Each processing element is independent of each other while processing hence no data dependency in MIMD.
- iv) Each Processing Element (PEs) can execute different program at the same time independent of each other.
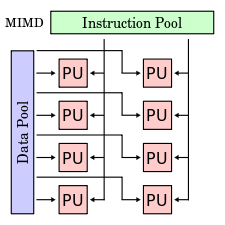
fig. MMID Architecture
- v) In MIMD class of machines each processor fetches its own instruction and operates on its own data.
- vi) Mainly there are two types of MIMD Architectures.
- Shared Memory MIMD Architecture.
- Distributed Memory MIMD Architecture.
- SIMT(Single Instruction Multiple Thread).
- i) Single Instruction Multiple Thread (SIMT) architecture has been developed to achieve high throughput computing with high energy efficiency.
- ii) In today’s computing field SIMT processors are used mainly for Graphic Processor Units (GPU).
iii) The SIMT architecture is created with the combined supports from the software and hardware sides.
- iv) The hardware architecture side in SIMT provides an approach for the conversion of scaler instructions into vector-style single-instruction multiple data (SIMD) processing for the achievement of energy efficiency.
- v) On the other hand the software side, the SIMT programming model for example CUDA provide facilities to achieve data parallelism to be implemented as task- level parallelism.
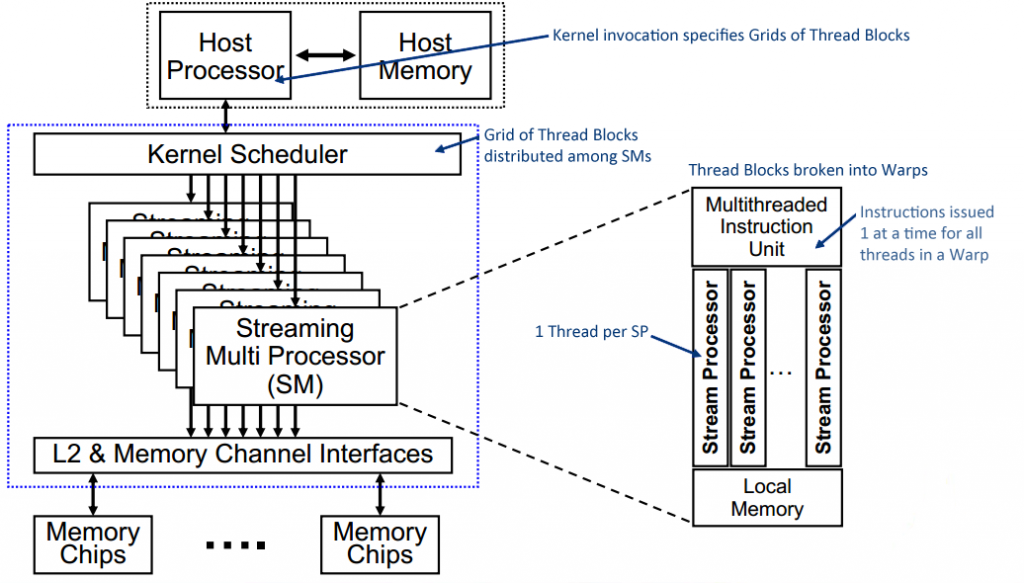
Fig: SIMT Architecture
Q1) b) Explain Basic Working Principle of VLIW Processor.
- i) Very Long Instruction Word(VLIW) are one of the suitable options to achieve Instruction Level Parallelism in programs. This means VLIW architectures can run more than one instruction at a same time in a program.
- ii) The following are some of the points can be considered as principles on which Very Long Instruction Word(VLIW) Processor works.
- VLIW processor’s basic aim is to speeding up the computation by achieving Instruction Level Parallelism (ILP).
- VLIW uses same hardware core as superscalar processors with multiple Execution Units (EUs)
working in parallel.
- In VLIW Processor, an instruction consists of more than one operations in which typical word length is from 52 bits to 1 Kbits.
- All the operations in the instruction are executed in a lock-step mode.
- The VLIW Processor is dependent on compiler to find the parallelism and the scheduled dependency in the program code.
Q2) a) Write a note on IBM Cell Broadband Engine (CBE).
- i) The Cell Broadband Engine (Cell BE) processor is the first implementation of the Cell Broadband Engine Architecture (CBEA), developed jointly by Sony, Toshiba, and IBM. In addition to Cell BE’s use in the upcoming Sony PlayStation® 3 console, there is a great deal of interest in using it in Cell BE-based workstations, media-rich electronics devices, video and image processing systems, as well as several other emerging applications.
- ii) The Cell BE includes one POWER™ Processing Element (PPE) and eight Synergistic Processing Elements (SPEs). The Cell BE architecture is designed to be well-suited for a wide variety of programming models, and allows for partitioning of work between the PPE and the eight SPEs. This paper shows that Cell BE can outperform other state-of-the-art processors by approximately an order of magnitude, or more in some cases.
iii) Until recently, improvements in the performance of general-purpose processor systems were primarily derived from higher processor clock frequencies, wider issue super-scalar or deeper super-pipeline designs. However, without a commensurate increase in the memory speed, these approaches only led to increased memory latencies and even more complex logic to hide them. Further, not being able to have a large number of concurrent accesses to memory, complex cores end up under-utilizing the execution pipelines and memory bandwidth. Invariably the end results can be poor utilization of the chip area and a disproportionate increase in power dissipation relative to overall performance.
Q2) b) Write a note on Dataflow Model.
- i) The dataflow model of computation is based on the graphical representation of programs in which operations are represented by nodes and arcs are used to represent dependencies.
- ii) The parallel processing activities under dataflow model of computing provides various properties to solve the computing problems in efficient ways. Some of the properties associated with dataflow computing model are:
- Asynchronous Executions:
The dataflow model of computations on asynchronous by nature. This means an instruction can only execute if all its required operands are available. This provides the nature of implict synchronization for parallel activities in dataflow computing model.
- No Sequencing.
In dataflow model of computing instructions are not necessary to execute in any sequential fashion. This dataflow model only based on data dependencies in the program and other than this no sequencing is expected.
- Dataflow Representation.
In dataflow model of computing no sequencing required and it makes the possibility of dataflow representation of a program. The dataflow representation of a program provides the use of all forms of parallel program execution without the assistance of any explict tools of parallel executions.
Q3) a) Differentiate between Thread and Process. For Multi Threading Implementation there is implicit support of architecture. Justify.
| Sr No | Process | Thread |
| 1 | An executing instance of a program is called a process. | A thread is a subset of the process. |
| 2 | It has its own copy of the data segment of the parent process. | It has direct access to the data segment of its process. |
| 3 | Processes must use inter-process communication to communicate with sibling processes. | Threads can directly communicate with other threads of its process. |
| 4 | Processes have considerable overhead. | Threads have almost no overhead. |
| 5 | New processes require duplication of the parent process. | New threads are easily created. |
| 6 | Processes can only exercise control over child processes. | Threads can exercise considerable control over threads of the same process. |
| 7 | Any change in the parent process does not affect child processes. | Any change in the main thread may affect the behavior of the other threads of the process. |
| 8 | Run in separate memory spaces. | Run in shared memory spaces. |
| 9 | Most file descriptors are not shared. | It shares file descriptors. |
| 10 | There is no sharing of file system context. | It shares file system context.
|
| 11 | It does not share signal handling. | It shares signal handling. |
| 12 | Process is controlled by the operating system. | Threads are controlled by programmer in a program. |
| 13 | Processes are independent. | Threads are dependent. |
- i) In computer architecture, multithreading is the ability of a central processing unit (CPU) or a single core in a multi-core processor to execute multiple processes or threads concurrently, appropriately supported by the operating system.
- ii) One set of solutions for increasing the performance of sequential programs is to apply an even higher degree of speculation in combination with a functional partitioningof the processor.
iii) Here thread-level parallelism is utilized, typically in combination with thread-level speculation.
A thread in such architectures refers to any contiguous region of the static or dynamic instruction sequence.
- iv) The term implicit multithreaded architecture refers to any architecture that can concurrently execute several threads from a single sequential program. The threads may be obtained with or without the help of the compiler.
- v) Examples of such architectural approaches are the multiscalar [16, 17, 18, 19], the trace processor [20,21, 22], the single-program speculative multithreading architecture [23], the superthreaded architecture [24, 25], the dynamic multithreading processor [26] and the speculative
multithreaded processor [27].
- vi) Some of these approaches may rather be viewed as very closely coupled CMPs, because multiple subordinate processing units execute different threads under the control of a single sequencer unit, whereas a multithreaded processor may be characterizedby a single processing unit with a single or multiple-issuepipeline able to process instructions of different threads
concurrently.
vii) All need some kind of architecture that is able to pursue two threads in parallel typically by assuming multithreaded processor hardware.
viii) Closely related to implicit multithreading are architectural proposals that only slightly enhance a superscalar processor by the ability to pursue two or more threads only for a short time. In principle, predicationis the first step in this direction.
viii) An enhanced form of predication is able to issue and execute a predicated instruction even if the predicate is not yet solved. A further step is dynamic predication as applied for the Polypath architecture that is a superscalar enhanced to handle multiple threads internally.
- ix) Another step to multithreading is simultaneous subordinate microthreading which is a modification of superscalars to run threads at a microprogram level concurrently.
Q3) b) Explain how ‘pthread_mutex_trylock’ reduce locking overhead ?
Syntax:
#include <pthread.h>
int pthread_mutex_trylock(pthread_mutex_t *mutex);
Service Program Name: QP0WPTHR
Default Public Authority: *USE
Threadsafe: Yes
Signal Safe: Yes
The pthread_mutex_trylock() function attempts to acquire ownership of the mutex specified without blocking the calling thread. If the mutex is currently locked by another thread, the call to pthread_mutex_trylock() returns an error of EBUSY.
A failure of EDEADLK indicates that the mutex is already held by the calling thread.
Mutex initialization using the PTHREAD_MUTEX_INITIALIZER does not immediately initialize the mutex. Instead, on first use, pthread_mutex_timedlock_np() or pthread_mutex_lock() or pthread_mutex_trylock() branches into a slow path and causes the initialization of the mutex. Because a mutex is not just a simple memory object and requires that some resources be allocated by the system, an attempt to call pthread_mutex_destroy() or pthread_mutex_unlock() on a mutex that was statically initialized using PTHREAD_MUTEX_INITIALIZER and was not yet locked causes an EINVAL error.
The maximum number of recursive locks by the owning thread is 32,767. When this number is exceeded, attempts to lock the mutex return the ERECURSE error.
Basically, the producer produces goods while the consumer consumes the goods and typically does something with them.
In our case our producer will produce an item and place it in a bound-buffer for the consumer. Then the consumer will remove the item from the buffer and print it to the screen.
A buffer is a container of sorts; a bound-buffer is a container with a limit. We have to be very careful in our case that we don’t over fill the buffer or remove something that isn’t there; in c this will produce a segmentation fault.
What: A synchronization tool used in concurrent programming
Where: We will use semaphores in any place where we may have concurrency issues. In other words any place where we feel more than one thread will access the data or structure at any given time.
When: To help solve concurrency issues when programming with threads.
Why: Think about how registers work in the operating system for a second. Here is an example of how registers work when you increment a counter-
register1 = counter;
register1 = register1 + 1;
counter = register1;
Now image two threads manipulating this same example but one thread is decrementing–
(T1) register1 = counter; [register1 = 5]
(T1) register1 = register1 + 1;[register1 = 6]
(T2) register2 = counter; [register2 = 5]
(T2) register2 = register2 – 1; [register2 = 4]
(T1) counter = register1; [counter = 6]
(T2) counter = register2;[counter = 4]
Because both threads were allowed to run without synchronization our counter now has a definitely wrong value. With synchronization the answer should come out to be 5 like it started.
How: We implement a semaphore as an integer value that is only accessible through two atomic operations wait() and signal(). Defined as follows:
/* The wait operation */
wait(S) {
while(S <= 0); //no-operation
S–;
}
/* The signal operation */
signal(S) {
S++;
}
S: Semaphore
The operation wait() tells the system that we are about to enter a critical section and signal() notifies that we have left the critical section and it is now accessible to other threads.
Therefore:
wait(mutex);
//critical section where the work is done
signal(mutex)
//continue on with life
Mutex stands for mutual exclusion. Meaning only one process may execute the section at a time.
We have an example that demonstrates how semaphores are used in reference to pthreads coming up right after this problem walk-through.
Basically, we are going to have a program that creates an N number of producer and consumer threads. The job of the producer will be to generate a random number and place it in a bound-buffer. The role of the consumer will be to remove items from the bound-buffer and print them to the screen. Remember the big issue here is concurrency so we will be using semaphores to help prevent any issues that might occur. To double our efforts we will also be using a pthread mutex lock to further guarantee synchronization.
The user will pass in three arguments to start to application: <INT, time for the main method to sleep before termination> <INT, Number of producer threads> <INT, number of consumer threads>
We will then use a function in initialize the data, semaphores, mutex lock, and pthread attributes.
Create the producer threads.
Create the consumer threads.
Put main() to sleep().
Exit the program
Q3) b) Describe Barrier Synchronization for Shared Address Space Model.
- i) In MPI programming, point to point communication is handled using message passing whereas global synchronization is done using collective communications.
- ii) Important point while using communication is synchronization point among processes.
iii) MPI provides special function which is designed and implemented for synchronization named as MPI_Barrier().
- iv) The working of this function is such a way that no process a allowed to cross a barrier untill all the processes have reached up to that barrier in their respective codes.
- v) Syntax: int MPI_Barrier(MPI_Communication)
- vi) The argument passed to this function is the communicator. A group of processes need to be synchronized are defined in communicator. Calling process blocks until all the processes in the given communicator have called it. This means the call only returns when all processes have entered the call.
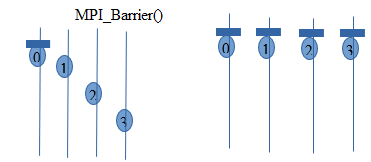
vii) The MPI_Barrier() function is invoked by process 0.
viii) When Process 0 reaches barrier, it stops and wait for remaining process to reach to the barrier point.
- ix) After every process reaches barrier point, the execution continues. Like this synchronization is achieved using Barrier.
Q5) a) Write pseudo-code for parallel quick sort.
Build-tree (int A[], int n)
{
for each process:
{
root = i; //shared memory
Parent[i] = root;
lc[i] = rc[i] = n+1;
}
repeat for each process i not equal to root
{
if(A[i] < A[Parent[i]]) or
(A[i] == A[Parent[i]] and i<parent[i])
{
lc [Parent[i]] = i; //shared memory
if (i = lc [Parent[i]])
return;
Parent[i] = lc[Parent[i]];
}
else
{
rc [Parent[i]] = i; //shared memory
if(i == rc[Parent[i]])
return;
Parent[i] = rc [Parent[i]];
}
}
}
Q5) b) How Pivot Selection is crucial factor for algorithm Performance?
- i) Choosing a random pivot minimizes the chance that you will encounter worst-case O(n2) performance (always choosing first or last would cause worst-case performance for nearly-sorted or nearly-reverse-sorted data).
- ii) Choosing the middle element would also be acceptable in the majority of cases.
iii) In quicksort, after selecting the pivot, all the elements smaller than pivot moves to left of the pivot and all the elements larger than pivot moves to the right of the pivot. This can be done efficiently in linear time and in-place.
- iv) Next step is to recursively sort the left and right sublists. Quicksort is among the fastest sorting algorithms in practice.
- v) The worst case time complexity of quicksort is O(n2) when the list is already sorted in either ascending or descending order and leftmost or rightmost element is selected as pivot.
- vi) A better way is to choose the median value from the first,the last and the middle element of the array. We can also used Randomized Quicksort for random selection of pivot.
vii) If the range of the numbers in the list of elements is too varying, then the median method does not help in reducing the complexity. In such cases, median of 5 or more can be used.
viii) If the pivot element is optimal then only complexity of Quick-sort will be O(logn).
Q6) a) Explain Sorting Network with suitable Diagram.
- i) In general, Sorting network is made up od series of columns. Each column contains number of comparators, that are connected in parallel.
- ii) The number of columns present in the network is called as depth of the network.
iii) Comparator plays an important role in the network. It is a device which takes two inputs a and b, and generates two outputs a’ and b’.
- iv) There are two types of comparators: increasing and decreasing.
- v) In an increasing comparator a’ = min(a,b) , b’ = max(a,b).
- vi) In a decreasing comparator a’ = max(a,b), b’ = max(a,b).
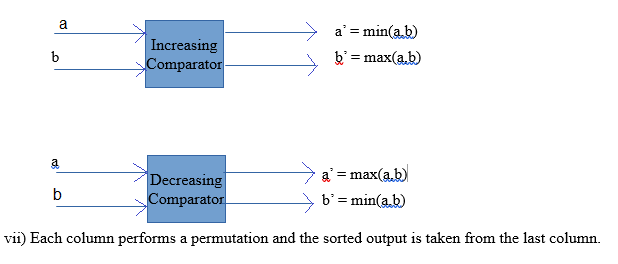
vii) Each column performs a permutation and the sorted output is taken from the last column.
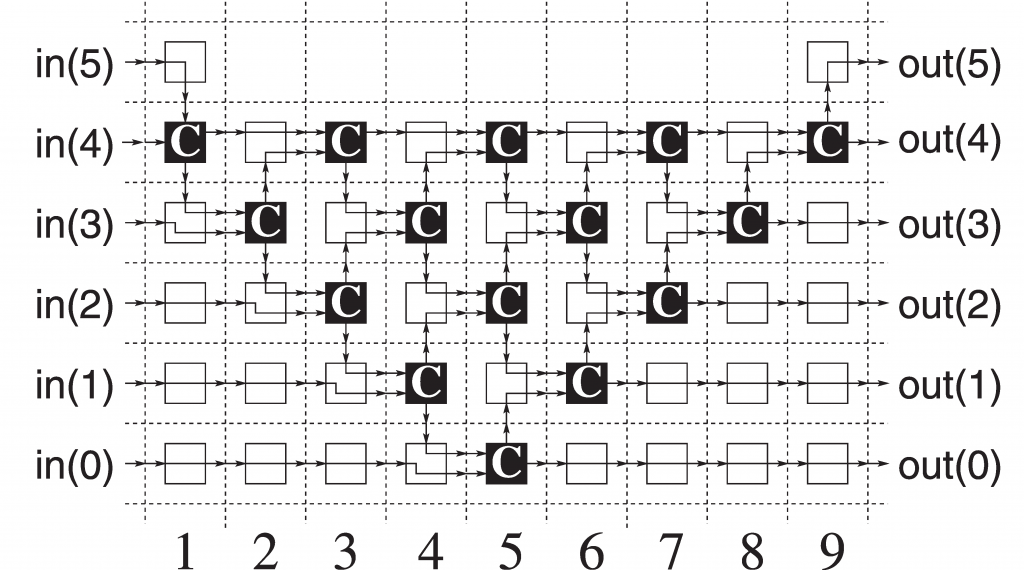
Fig: Schematic diagram of a sorting network
Q6) b) Explain Single Shortest Path Algorithm with suitable Example.
Single Source Shortest Path
- i) A traveler wishes to find a shortest distance between New Delhi and Visakhapatnam, in a road map of India in which distance between pair of adjacent road intersections are marked in kilometers.
- ii) One possible solution is to find all possible routes between New Delhi and Visakhapatnam, and find the distance of each route and take the shortest.
iii) There are many possible routes between given cities. It is difficult to enumerate all of them.
- iv) Some of these routes are not worth considering. For example, route through Cinnai, since it is about 800KM out of the way.
- iv) The problem can be solved efficiently, by modeling the given road map as a graph and find the shortest route between given pair of cites as suitable (single source shortest paths) graph problem.
Graph Representation of the road map: The intersections between the roads are denoted as vertices and road joining them as edge in the graph representation of the given road map.
- i) Single Source Shortest Path problem: Given a graph G = (V, E), we want to find the shortest path from given source to every vertex in the graph.
- ii) The problem is solved efficiently by Dijkstra using greedy strategy. The algorithm is known as Dijkstra’s algorithm.
iii) The method works by maintaining a set S of vertices for which shortest path from source v0 is found. Initially, S is empty and shortest distance to each vertex from source is infinity.
- iv) The algorithm repeatedly selects a vertex viin V – S to which path form source is shorter than other vertices in V-S, adds to S, and estimates the shortest distance to other vertices from vi.
Algorithm Dijkstra_shortest_path(G, v_0)
Step 1: for each vertex vi in V do
Step 2:dist[vi} = infinity
Step 3: distance[v0] = 0;
Step 4:for each vertex v_i in V do
Step 5: insert(Q, vi)
Step 6: S = empty
Step 7: while (Q not empty) do
Step 8: vi = Min(Q)
Step 9: for each vertex vj adjacent to vi do
Step 10: distance[vj] = Minimum (distance[vj], distance[vi] + w[vi,vj])
- Consider the Following Graph
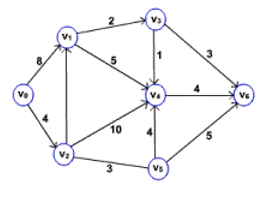
- The following sequence of figures shows the way of finding the shortest path from source vertex v0.
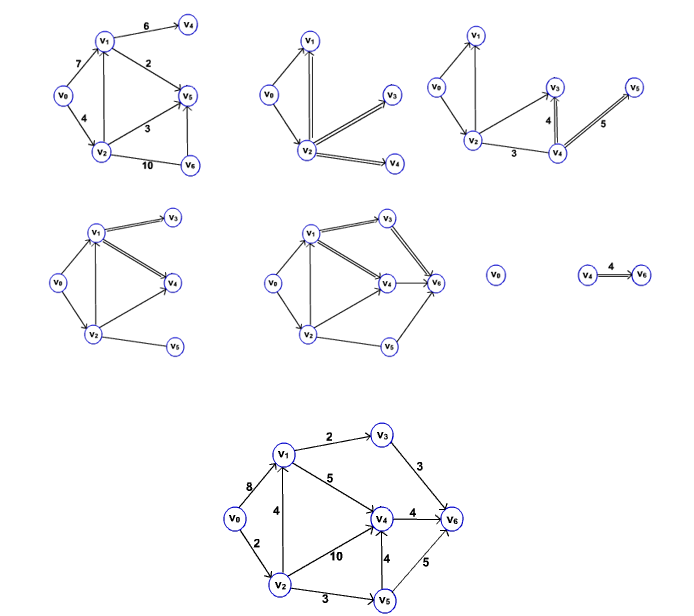
- The event queue in Dijkstra’s algorithm can be implemented using array or heap.
All pairs shortest path
- Problem: In a given weighted directed graph find the shortest path between every pair of vertices.
- This problem can be solved by repeatedly invoking the single source shortest path algorithm for each vertex as a source.
- Another way of solving the problem is using dynamic programming technique.
Q7) a) Write Short Notes on (Any Two)
- Discrete Optimization Problem.
- Parallel Best-First Search.
- Quantum Computers.
- Discrete Optimization Problem.
- i) A discrete optimization problem is a tuple (S,f), where S is set of all solutions satisfy the given constraints. S can be either finite or countably infinite. S is called the set of possible or feasible solutions.
- ii) f is a function from S to the set of real numbers R, represented as, f:S —> R
iii) It is called as cost function.
- iv) The main task in discrete optimization problem is to find optimal solution xopt from the set of feasible solutions S, such that
∀ x ∈ S, f(xopt) <= f(x)
- v) Discrete Optimization Problem can be solved using following methods.
- Brute force Search.
- Maximization-Minimization.
- Parallel Best First Search.
- i) Best First Search (BFS) algorithm can be used to search both trees and graphs. This algorithm uses heuristics to select the portion of search space.
- ii) The nodes which are near to result or seem to give a result are assigned with smaller heuristic values and nodes away from the result are assigned with larger heuristic method.
iii) This algorithm maintains two lists: an open list and a closed list. Initially, the first node is placed on the open list. The algorithm uses a predefined heuristic evaluation function. This function measures how likely the node can get closer to result.
- iv) The open list is sorted as per this function.
- v) In each step, the most promising node from the open list is removed. If it is the required resulting node, then the algorithm is terminated.
- Quantum Computers.
- i) Quantum is the minimum amount of any physical entity which is involved in any communication.
- ii) The computer which is designed by using the principles of quantum physics is called quantum computer.
iii) A quantum computer stores the information using special types of bits called quantum bit represented as |0> and | 1 >.
- iv) This increases the flexibility of the computations. It performs the calculations based on the laws of quantum physics.
- v) The quantum bits are implemented using the two energy levels of an atom. An excited state represents | 1> and a ground state represents | 0>.
- vi) Quantum gates are used to perform operations on the data. They are very similar to the traditional logical gates.
vii) Since the quantum gates are reversible, we can generate the original input from the obtained output as well.
viii) A quantum computer has the power of atoms to perform any operation. It has a capability of processing millions of operations parallely.
Q7) b) Share your thoughts about how HPC will help to promote “Make in India” Initiative.
- i) Make in India is an initiative launched by the Government of India to encourage multi national as well as national companies to manufacture their products in India. It was launched by Prime Minister Narendra Modi on 25 september 2014. After the initiation of the programme in 2015, India emerged as the top destination for foreign direct investment.
- ii) Make in India focuses on the following sectors of the economy:
- Automobiles
- Biotechnology
- Construction
- Chemicals
- Electronic System
- Aviation
- Mining
- Railways
- Roads and Highways.
- Oil and Gas.
iii) The Mission Make in India also includes development of highly Professional High Performance Computing (HPC) aware human resource for meeting challenges of development of these applications. As far as HPC are considered, the construction of super computer is a big achievement. Till now India has developed many supercomputers, among them, 8 computers are in the list of world’s best 500 supercomputers.
Q8) a) Write a Short note on (any two)
- Parallel Depth First Search.
- Search Overhead factor
- Power aware Processing.
- Parallel Depth First Search.
- i) To solve a discrete optimization problem, depth first search is used if it can be formulated as tree search problem. Depth-first search can be performed in parallel by partitioning the search space into many small, disjunct parts (subtrees) that can be explored concurrently. DFS starts with initial node by generating its successors.
- ii) If any node has no successors, then it indicates that there is no solution in that path. Thus backtracking is done and continued to expand another node. Following figure gives the DFS expansion of the 8-puzzle.
iii) The initial configuration is given in (A) .There are only two possible moves,Blank up or blank right. Thus from (A) two children or successors are generated. Those are (B) and (C).
- iv) This is done in step 1. In step 2, any one of (B) and (C) is selected. If (B) is selected then its successors (D), (E) and (F) are generated. If (C) is selected then its successors (G), (H) and (I) are generated.
- v) Assuming (B) is selected, and then in the next step (D) is selected. It is clear that (D) is same as (A), thus backtracking is necessary. This process is repeated until the required result is found.
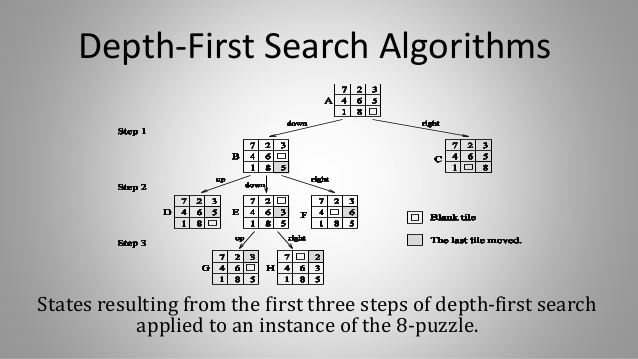
- Search Overhead Factor.
Parallel search algorithms incur overhead from several sources. These include communication overhead, idle time due to load imbalance, and contention for shared data structures. Thus, if both the sequential and parallel formulations of an algorithm do the same amount of work, the speedup of parallel search on p processors is less than p. However, the amount of work done by a parallel formulation is often different from that done by the corresponding sequential formulation because they may explore different parts of the search space.
Let W be the amount of work done by a single processor, and Wp be the total amount of work done by p processors. The search overhead factor of the parallel system is defined as the ratio of the work done by the parallel formulation to that done by the sequential formulation, or Wp/W. Thus, the upper bound on speedup for the parallel system is given by p x(W/Wp). The actual speedup, however, may be less due to other parallel processing overhead. In most parallel search algorithms, the search overhead factor is greater than one. However, in some cases, it may be less than one, leading to superlinear speedup. If the search overhead factor is less than one on the average, then it indicates that the serial search algorithm is not the fastest algorithm for solving the problem.
To simplify our presentation and analysis, we assume that the time to expand each node is the same, and W and Wp are the number of nodes expanded by the serial and the parallel formulations, respectively. If the time for each expansion is tc, then the sequential run time is given by TS = tcW. In the remainder of the chapter, we assume that tc = 1. Hence, the problem size W and the serial run time TS become the same.
- Power aware Processing.
- i) In high-performance systems, power-aware design techniques aim to maximize performance under power dissipation and power consumption constraints. Along with thsi, the low-power design techniques try to reduce power or energy consumption in portable equipment to meet a desired performance. All the power a system consumes eventually dissipates and transforms into heat.
Q8) b) Define term FIPC and Elaborate its use to Indian Society.
- i) Foreign Investment Promotion Council has been setup by the government of india in order to encourage more foreign direct investment into the country. By doing this Foreign Investment Promotion Council has helped in the growth of Country’s economy.
- ii) Foreign Direct Investment(FDI) flows are usually preferred over other forms of external finance because they are non-debt creating, non volatile, and their returns depend on the performance of the projects financed by the investors.
iii) The FIPC should be transformed into the primary arm of the government for promoting FDI in india, with the department of Industrial Policy and Promotion continuing to act as its secretariat.
- iv) FIPC can be activated and broad based with participation of State Governmens representative’s, experts,industry associations, Financial Institutions, MNC’s etc.




